 OpenPipe
OpenPipe
OpenPipe 是面向开发者和 AI 应用团队的 AI训练模型 平台,公开文档覆盖数据集、微调、DPO、评估、Criteria、Chat Completions、Caching、部署与外部模型接入;其 ART 项目则把 Agent 强化学习训练扩展到多步真实任务。
OpenPipe 的核心参数与统计
OpenPipe 的公开产品形态可以分成两条主线:一条是托管式 LLM 微调与评估平台,围绕数据集、训练任务、评估表和推理部署工作;另一条是 ART,即 Agent Reinforcement Trainer,把强化学习训练扩展到多步 Agent 工作流。按官方页面和文档定位,它更适合归入模型训练类,而不是泛数据处理工具。
| 项目 | 当前公开信息 |
|---|---|
| 官方入口 | https://openpipe.ai/ |
| 文档入口 | https://docs.openpipe.ai/ |
| 分类 | ai-model-training |
| 主要能力 | Fine Tuning、DPO、Evaluations、Criteria、Chat Completions、Caching、Deployments、External Models |
| Agent 训练能力 | ART 使用 GRPO 训练多步 Agent,支持 Qwen、GPT-OSS、Llama 等模型路线 |
| 平台形态 | Web 控制台、API、官方开源训练项目 |
| 公开联系邮箱 | [email protected] |
| ART 公开仓库统计 | 约 10,150 stars、906 forks,Apache-2.0 许可 |
定位边界:OpenPipe 的价值不在于替代通用模型服务,而在于把已有业务日志、标注样本、偏好数据和评估标准变成可训练、可对比、可上线的模型资产。对于只需要一次性调用大模型的团队,它的训练和评估体系会显得偏重。
OpenPipe 的用户与市场认可
OpenPipe 的认可度主要来自开发者场景和公开代码生态。ART 仓库的公开描述是“Agent Reinforcement Trainer”,并明确把 GRPO、多步 Agent、Qwen、GPT-OSS、Llama 等关键词放在项目定位中;这说明它服务的不是普通聊天前端,而是希望把 Agent 在真实任务中的失败样本继续训练成能力提升的工程团队。
开发者信号:ART 公开仓库显示约 10,150 stars、906 forks,默认语言为 Python,许可为 Apache-2.0,主题覆盖 agent、agentic-ai、grpo、llms、lora、qwen、reinforcement-learning、rl。这个规模说明 OpenPipe 在 Agent 强化学习训练方向已经形成较强的开发者关注,但企业客户数量、营收和付费规模未公开。
产品信号:官方文档左侧导航覆盖 Fine Tuning、DPO、Evaluations、Criteria、Chat Completions、Caching、Deployments 与 External Models,表明 OpenPipe 并不是单点训练脚本,而是把数据、训练、评估、推理和外部模型接入串成一个闭环。
OpenPipe 的成本优势:把训练、评估与托管成本拆到可核算单元
OpenPipe 的成本优势来自“按训练规模、推理 token 或计算单元拆分”的计费方式。团队可以先按模型类别估算训练费用,再按推理量选择 per-token 或 compute unit 模式,而不是在试点阶段直接进入定制企业合同。
C 端/个人:OpenPipe 不是面向普通个人聊天的免费应用,公开定价页主要面向开发者和组织训练、部署模型。个人开发者可以通过 Web 与 API 试验,但费用取决于训练数据量、模型类别和推理使用量。
开发者/API:训练按模型大小和数据集 token 数计费;托管推理可以按 token 或 CU 小时计费。第三方模型经 OpenPipe 微调时,官方说明不加额外 markup,调用和费用由对应模型供应商标准费率承担。
企业/私有化:企业计划覆盖 volume discounts、on-premises deployment options、dedicated support、custom SLAs、advanced security features、increased data storage。具体合同、SLA 和部署边界需要商务确认。
| 计费对象 | 官方公开计费方式 | 公开价格/边界 |
|---|---|---|
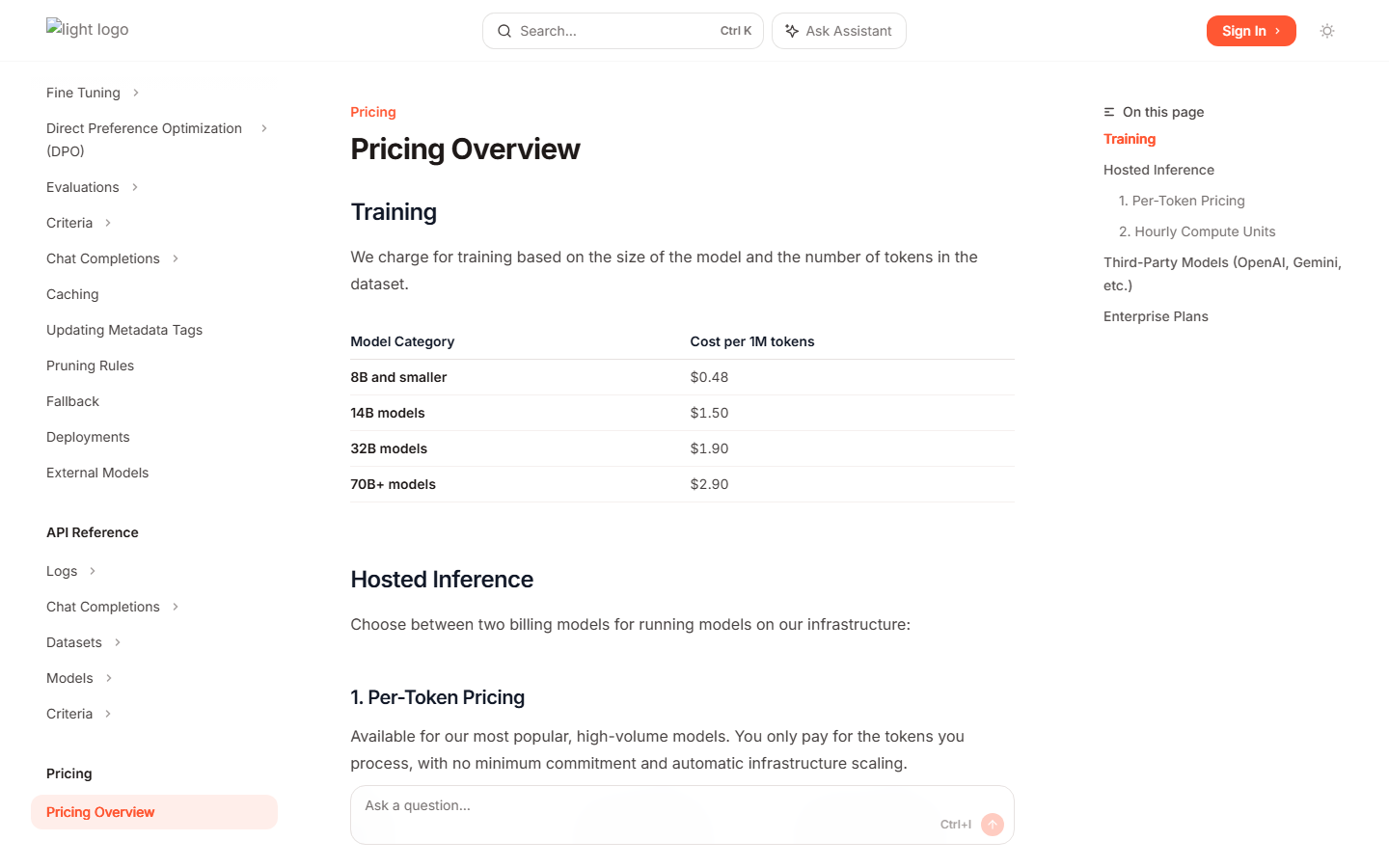
| Training 8B and smaller | 按 1M tokens | $0.48 |
| Training 14B models | 按 1M tokens | $1.50 |
| Training 32B models | 按 1M tokens | $1.90 |
| Training 70B+ models | 按 1M tokens | $2.90 |
| Hosted Inference Llama 3.1 8B Instruct | 输入/输出 1M tokens | $0.30 / $0.45 |
| Hosted Inference Llama 3.1 70B Instruct | 输入/输出 1M tokens | $1.80 / $2.00 |
| Compute Unit | 按 CU hour | 8B/12B 为 $1.50,32B/14B 为 $6.00,72B/70B 为 $12.00 |
OpenPipe 的主要功能
- 数据集与训练入口:Fine-Tuning 快速开始页要求先创建 dataset,并导入至少 10 条训练数据;训练时默认会保留 10% 数据作为测试集,用于评估新模型输出。
- 微调任务管理:官方流程包含选择训练数据、命名模型、调整超参数、启动训练和查看训练完成模型,适合把生产样本转成可复用模型版本。
- DPO 与偏好优化:官方导航单独提供 Direct Preference Optimization,适合已有偏好样本、希望让模型更贴近人工判断或业务标准的场景。
- 评估体系:Evaluations 支持 code evaluations、criterion evaluations、head-to-head evaluations,分别对应确定性任务、自由文本任务和多模型快速对比。
- 推理与缓存:Chat Completions、Caching、Deployments 与 External Models 让训练后的模型进入推理链路,并与外部模型供应商形成统一调用面。
- Agent 强化学习:ART 用 GRPO 训练多步 Agent,适合从真实任务执行轨迹中学习,而不仅是对单轮 prompt 输出做微调。
这些功能组合的关键在于闭环:先收集数据和日志,再训练模型,再用评估表判断输出质量,最后部署到推理链路。缺少评估标准的团队即使完成训练,也很难判断模型是否真的优于基座模型。
OpenPipe 的模型与版本演进
OpenPipe 没有像传统软件那样在官网统一展示语义化版本号,因此更适合用公开产品里程碑描述演进。当前官网标题显示“RL For Agents”,说明产品叙事已经从早期微调平台进一步扩展到 Agent 强化学习训练;官方文档仍保留 Fine Tuning、DPO、Evaluations 和推理托管能力。
| 阶段 | 版本/里程碑 | 日期 | 公开含义 |
|---|---|---|---|
| 微调平台 | OpenPipe Fine-Tuning Platform | ~2024-09 | 以数据集、训练任务、模型部署和评估为核心的托管训练平台,暂无官方精确发布日期 |
| ART 公开项目 | OpenPipe ART | 2025-03-10 | 官方公开仓库创建,定位为 Agent Reinforcement Trainer |
| 当前官网定位 | OpenPipe RL for Agents | ~2026-06 | 官网标题显示 RL For Agents,产品叙事聚焦 Agent 强化学习训练,暂无官方精确发布日期 |
版本判断:对生产环境而言,OpenPipe 的“版本”更应按能力面和部署依赖来验收,而不是只看版本号。微调、评估、推理托管和 ART 训练链路涉及不同运行环境,试点时需要固定数据集、基座模型、评估标准和推理成本口径。
OpenPipe 的技术优势
闭环训练机制:OpenPipe 把 dataset、fine-tuning、evaluations、deployments 放在同一套文档和产品路径里。机制上,训练数据先进入数据集,再形成训练任务,随后用测试集和评估规则比较输出;效果上,团队能更清楚地看到模型是否真的改善;适用场景是分类、抽取、客服、摘要、代码生成等有稳定样本和评价标准的任务。
多评估模式:code evaluations 适合确定性输出,criterion evaluations 适合自由文本,head-to-head evaluations 适合多个模型之间快速比较。机制上,它把“看起来不错”的主观判断拆成不同评估方法;效果上,减少模型上线前的盲区;适用场景是需要持续比较基座模型、微调模型和外部模型的开发团队。
Agent 强化学习路线:ART 面向多步 Agent,通过 GRPO 做在岗训练。机制上,它关注任务执行轨迹和奖励信号;效果上,训练目标更接近真实工作完成度;适用场景是工具调用、长链路任务、代码 Agent 和需要持续改进策略的自动化系统。
如何使用 OpenPipe
OpenPipe 的使用路径通常从数据集开始,而不是从模型参数开始。开发团队先把日志或标注样本整理为训练 entries,进入 Web 控制台或 API 创建 dataset;随后选择基座模型、命名模型、设置超参数并启动训练。训练完成后,再用默认测试集或自定义评估任务检查输出差异,最后将合格模型接入 Chat Completions 或部署链路。
Web 控制台路径:适合小团队快速验证,重点是看训练数据格式、默认测试集、超参数选择和评估表是否能覆盖业务任务。
API 路径:适合把生产日志、标注平台和 CI 评估流程串起来。API 路径的前提是团队已有稳定数据流和明确评价标准,否则自动化训练只会放大数据噪声。
ART 路径:适合 Agent 团队,把真实任务执行过程、奖励信号和模型策略迭代结合起来。它更接近工程训练框架,通常需要开发者理解强化学习、模型运行环境和评估指标。
OpenPipe 的产品定价
OpenPipe 的公开定价页把费用拆成 Training、Hosted Inference、Third-Party Models 和 Enterprise Plans。训练费用按模型类别和数据集 token 数计算;推理托管提供 per-token pricing 和 hourly compute units 两种方式;第三方模型通过 OpenPipe 微调时不额外加价,由对应供应商按标准费率结算。
训练费用:8B 及以下模型按 $0.48 / 1M tokens,14B 模型 $1.50 / 1M tokens,32B 模型 $1.90 / 1M tokens,70B+ 模型 $2.90 / 1M tokens。训练数据越大、模型越大,总训练费用越高。
推理费用:高量模型适合 per-token pricing;实验性或低量模型适合 CU hour。一个 Compute Unit 官方说明最多可处理 24 simultaneous requests per second,并在流量峰值后保留 60 秒。
企业费用:企业计划需要联系 [email protected],重点确认本地部署、折扣、SLA、支持、安全功能和数据存储条款。
OpenPipe 的应用场景
- 客服与运营文本模型:把历史工单、人工回复和质检标准整理成训练集,通过微调减少格式错误和语气偏差;验收重点是错误率、人工返工率和评估任务通过率。
- 信息抽取与分类:code evaluations 适合结构化抽取、标签分类、字段归一化等确定性任务;验收重点是准确率、召回率和边界样本表现。
- 多模型评估与路由:head-to-head evaluations 可用于比较基座模型、微调模型和外部模型,帮助决定哪些任务值得用小模型承接,哪些任务保留给更强模型。
- Agent 强化学习:ART 适合训练多步 Agent,例如工具调用、代码任务、检索后执行和工作流自动化;验收重点是任务完成率、失败恢复能力和单位任务成本。
OpenPipe 更适合“已经有数据和评价标准”的团队。如果业务任务还没有稳定定义,先做数据治理和评估标准会比直接训练模型更重要。
OpenPipe 的适用人群
- AI 应用开发团队:需要把生产日志转成微调数据,并通过评估流程判断模型是否值得上线。
- 平台与 MLOps 团队:需要统一管理训练、推理托管、外部模型和评估标准,关注成本、质量和可追溯性。
- Agent 工程团队:需要使用 GRPO 等强化学习方法训练多步 Agent,关注真实任务完成度而不是单轮文本分数。
- 数据标注与评测负责人:需要把人工标准变成可复用的 criterion、code 或 head-to-head evaluations。
不太适合的场景包括:没有训练数据、没有评估标准、只需要普通聊天入口、或者团队无法承担模型训练与部署维护成本。此时直接使用通用模型 API 往往更轻。
OpenPipe 的总结与展望
OpenPipe 的核心竞争力在于把 LLM 微调、评估、推理托管和 Agent 强化学习训练放到同一条工程路径里。它不是面向大众的聊天产品,而是面向希望用数据持续改进模型表现的开发者平台;当团队已经积累生产日志、标注样本和明确评价标准时,OpenPipe 可以把“模型是否变好”从感觉判断变成可评估流程。
当前限制也很明确:公开资料没有披露完整客户数量、营收、企业合同细则和所有历史版本日期;ART 虽有活跃关注度,但强化学习训练本身对数据、奖励设计和工程环境要求较高。企业落地时建议先选择一个高频、边界清晰、可量化验收的任务试点,确认训练成本、评估收益、推理延迟和数据安全条款后,再扩展到更多业务线。
版本信息
- OpenPipe ART :官方 ART 仓库创建于 2025-03-10,描述为 Agent Reinforcement Trainer,面向多步 Agent 任务使用 GRPO 训练。
- OpenPipe RL for Agents :官网标题公开显示 OpenPipe 当前定位为 RL For Agents,官方文档同时保留微调、DPO、评估、推理托管和外部模型接入能力;暂无官方精确发布日期。
- OpenPipe Fine-Tuning Platform :官方文档公开的模型微调平台形态,覆盖数据集导入、训练、超参数调整、训练完成后的模型部署与评估;暂无官方精确发布日期。
用户评价