谷歌自家Android基准测试:Gemini成本为DeepSeek V4 Flash的17.5倍
谷歌Android Bench榜单显示Gemini 3.5 Flash单次运行成本$147,而DeepSeek V4 Flash仅$8.4,价差17.5倍。GPT-5.5以74分居首,国产模型GLM、Kimi、DeepSeek集体上榜。
谷歌自家基准测试翻车:Gemini成本为DeepSeek的17.5倍
谷歌更新了 Android Bench 榜单——一项专门衡量 AI 模型完成安卓开发任务能力的基准测试,对开发者选择模型有较强参考价值。结果颇具讽刺意味:谷歌在 I/O 2026 上高调宣称为"迄今最强 Flash 模型"的 Gemini 3.5 Flash 仅拿到 63.7 分排名第六,单次运行平均成本高达 $147.1(约合 996 元人民币),是整个榜单中最贵的模型。而 ![]() DeepSeek V4 Flash 单次运行成本仅 $8.4(约合 57 元人民币)——前者是后者的 17.5 倍。
DeepSeek V4 Flash 单次运行成本仅 $8.4(约合 57 元人民币)——前者是后者的 17.5 倍。
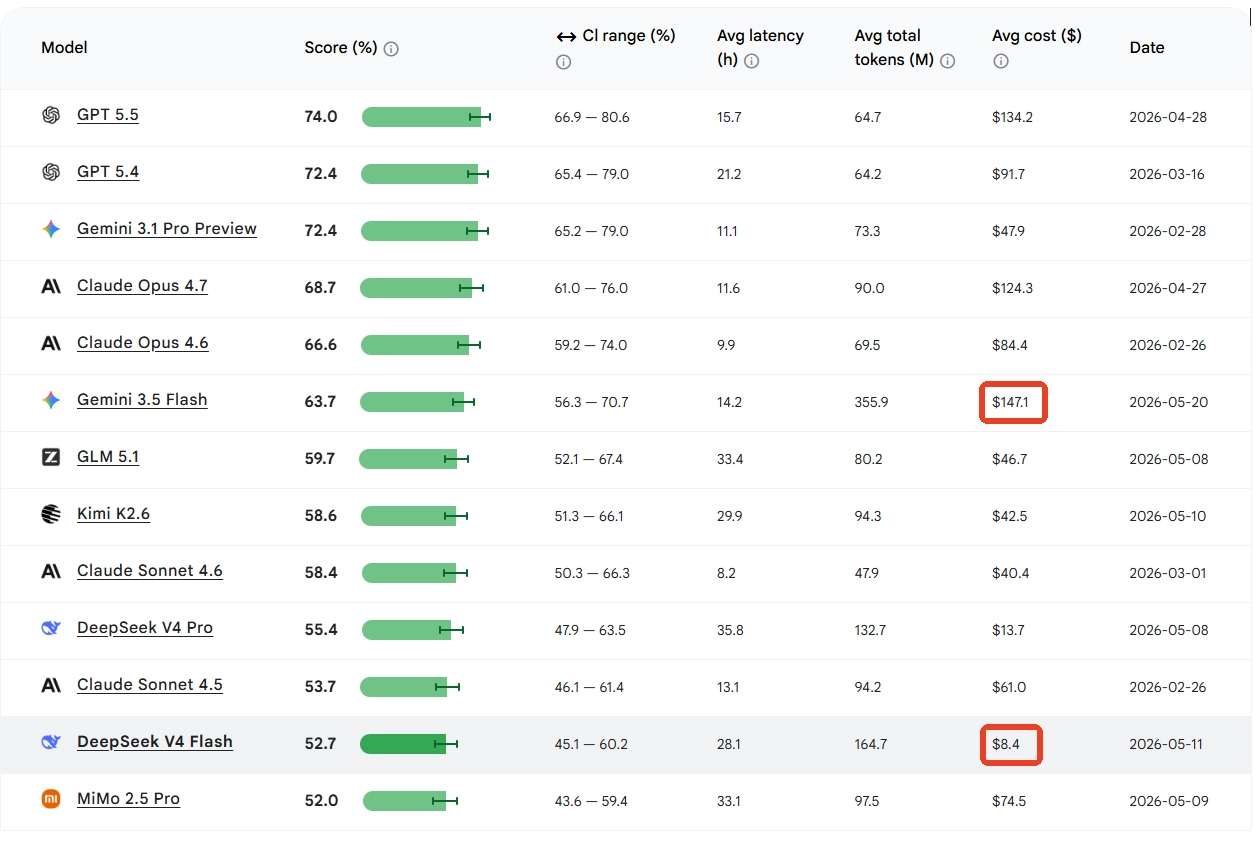
榜单成绩与成本明细:
| 排名 | 模型 | 得分 | 单次成本 |
|---|---|---|---|
| 1 | GPT-5.5 | 74.0 | — |
| 2 | GPT-5.4 | 72.4 | — |
| 3 | Gemini 3.1 Pro Preview | 72.4 | ~$49 |
| 4 | Claude Opus 4.7 | 68.7 | — |
| 5 | Claude Opus 4.6 | 66.6 | — |
| 6 | Gemini 3.5 Flash | 63.7 | $147.1 |
| 7 | 智谱 GLM 5.1 | 59.7 | — |
| 8 | Kimi K2.6 | 58.6 | — |
| 10 | DeepSeek V4 Pro | 55.4 | — |
| 12 | DeepSeek V4 Flash | 52.7 | $8.4 |
国产模型方面,智谱 GLM 5.1(59.7 分)、Kimi K2.6(58.6 分)、DeepSeek V4 Pro(55.4 分)三款同时上榜,体现中国 AI 模型在开发者工具领域的集体存在感。
谷歌在 I/O 2026 上曾宣称 Gemini 3.5 Flash 编码能力更稳健、输出速度最高可达竞争性前沿模型的 4 倍,且在部分内部基准测试中优于 Gemini 3.1 Pro。但 Android Bench 的真实安卓开发场景数据给出了截然不同的结论——不仅分数未进前五,性价比更被 DeepSeek V4 Flash 碾压。即便是谷歌自家设计的基准测试,也无法为自家模型挽回颜面。在开发者用脚投票的时代,厂商的营销话术正在被真实场景的性价比数据系统性证伪。
版权声明:本文内容来自
IT之家
。本平台对该内容进行了编译和整理,仅用于信息传播和学习交流之用。如有侵权,请联系我们进行处理。
用户评价